
![LLM Sandwich: Build Trustworthy Enterprise AI Systems [Guide]](/content/images/size/w2000/2026/04/WhatsApp-Image-2026-04-10-at-12.37.41-PM.jpeg)
You’ve used ChatGPT. Maybe Claude or Gemini. You type something in, you get something useful back. The Large Language Model (LLM) behind it understands language, reasons through it, and responds.
Now imagine that same model inside your organization.
For CTOs, Heads of AI/ML, enterprise architects, and digital leaders in regulated industries like BFSI, healthcare, and insurance—this is what introduces friction.
The model continues to do what it does best: generate responses. But it doesn’t understand business rules, data boundaries, or operational constraints. It has no built-in awareness of business logic or domain context.
As a result, AI in production often leads to failure due to:
- wrong AI outputs that break customer trust,
- skipped compliance rules that trigger regulatory risk and
- unchecked agents that spike AI compute cost.
The fix is simple: don't just deploy an LLM, wrap it with business rules and control layers. Let it do the thinking. Use business rules to control what it sees, what it says, and what it's allowed to do.
This approach is often referred to as the “LLM Sandwich.”
In this blog, we'll break down exactly how it works and how it becomes the foundation of AI that works in a demo and AI that works in production.
TABLE OF CONTENTS:
- Why LLMs Alone Don't Work in Enterprise Settings
- What Is the LLM Sandwich?
- What Happens Inside The Pre-LLM Layer?
├──Query Routing
├──Access Control
├──Context Retrieval
└──Model Selection - What Happens Inside The Post-LLM Layer?
├──Accuracy Checks
├──Compliance Enforcement
├──Sensitive Data Filtering
└──Human Escalation - What Enterprises Actually Get Out of the LLM Sandwich
- From AI Pilot to Production: How to Get There
- Frequently Asked Questions
Why LLMs Alone Don't Work in Enterprise Settings
- What is An LLM (Large Language Model)?
An LLM (Large Language Model) is software trained on enormous amounts of text. Books, articles, websites, code, conversations. From that training, it gets very good at one thing: understanding what you're asking and generating a response that sounds coherent and useful.
It doesn't think the way humans do. It predicts. Given your question, it produces the most statistically likely useful answer based on everything it was trained on. Most of the time, that's impressive. Sometimes, it's confidently wrong (a.k.a hallucinates).
That's fine when you're using it personally. You ask ChatGPT something, it gets it wrong, you try again. Low stakes. No consequences.
Enterprise settings are completely different environment.
That same response goes to a customer, a regulator, or an internal report. The people reading it assume it's been checked. They act on it.
On top of that, enterprises bring a set of requirements that LLMs were never designed to handle on their own. Like:
- Sensitive data. Your systems hold customer records, financial data, legal documents. The LLM has no concept of what it should and shouldn't access.
- Access rules. Not everyone in your organisation should see everything. The LLM doesn't know your org chart.
- Compliance obligations. Regulated industries have mandatory disclosures, audit trails, and documentation requirements. The LLM doesn't know your regulatory environment.
- Cost at scale. One person using an AI casually costs nothing significant. Thousands of employees and customers hitting it all day is a budget line that needs managing.
- Consistency. Businesses run on rules applied uniformly. An LLM applies patterns which means edge cases get handled differently every time.
None of this makes LLMs bad. It makes them incomplete. That's exactly the problem the LLM Sandwich solves.
What Is The LLM Sandwich?
The LLM Sandwich places your AI model between two deterministic processing layers. These layers are not AI. They are reliable, rule-based systems that do what AI cannot: enforce policies absolutely, validate facts against authoritative sources, and make cost-effective routing decisions.
How a query moves through the system:
Why a "sandwich"? The AI(LLM) is the filling: the intelligent, reasoning part. The pre- and post-processing layers are two sides of bread. Without bread, the filling goes everywhere. With it, you have something structured, useful, and safe to deliver.

What Happens Inside The Pre-LLM Layer?
Before a user's question ever reaches the AI model, the Pre-LLM layer runs a set of checks and decisions. Think of it as a control layer that governs access, context, and routing decisions before the model is invoked.
This layer typically performs four key functions:
A. Query Routing: Reducing Unnecessary AI Usage
This is one of the most important cost-control insights in enterprise AI: many questions have determinate answers that require no reasoning at all.
At scale, this routing decision compounds dramatically. If 40% of queries are pattern-matched and handled without AI, you have cut your AI spend almost in half, with faster response times and better accuracy on those queries.
The Pre-LLM layer routes to the AI only when genuine reasoning is needed—for example, multi-step queries, nuanced customer interactions, or responses that require natural-language tailoring.
B. Access Control: Why Business Rules Must Sit Outside the AI
Access control is a prime example of something that must never be delegated to an AI. If a user is not permitted to see certain data, that decision is made in the Pre-LLM layer (deterministically, not probabilistically).
C. Context Retrieval: Giving the AI What It Needs to Know
This is where Retrieval-Augmented Generation (RAG) comes in.
AI models are trained on data up to a certain point in time. They do not know about your updated return policy, your latest pricing, or the recent internal updates or communications from last Tuesday. RAG helps inject it.
The Pre-LLM layer solves this by searching your company's own knowledge base and injecting the relevant information into the question before the AI ever sees it.
D. Model Selection: Matching Query Complexity to the Right Tier
Not all AI queries are equally complex and the most capable (and expensive) AI models are not always the right choice.
| Query Type | What the System Does |
|---|---|
|
DETERMINISTIC Simple fact lookup (leave balance, store hours) |
Skips AI entirely and retrieves answers directly from structured databases. |
|
MID-TIER AI Standard question (product eligibility, policy query) |
Routes the request to a mid-tier, cost-effective model. |
|
PREMIUM AI Complex reasoning (financial portfolio analysis) |
Routes the request to a premium model for deeper reasoning and analysis. |
Organisations that implement this routing typically reduce their AI compute costs by half without any reduction in the quality of the answers that actually matter.

What Happens Inside The Post-LLM Layer?
The AI has generated an answer. Before that answer reaches your user, the Post-LLM layer runs it through a series of checks and ensures that output is safe, accurate, and compliant before it reaches the user.
A. Accuracy Checks: Preventing AI Hallucinations
Because the Pre-LLM layer injected context from your knowledge base, the Post-LLM layer can check whether the AI's answer is consistent with those source documents. For example, if the AI states a 90-day return policy but the source document specifies 30 days, the mismatch is caught before reaching the user.
B. Compliance Enforcement: Making Regulatory Requirements Automatic
In regulated industries, certain disclosures are not optional. A financial services firm must include risk warnings. A healthcare provider cannot make clinical guarantees. The Post-LLM layer checks for required language and either injects it automatically or escalates the response for human review.
C. Sensitive Data Filtering: What the AI Can't See, It Can't Leak
Even with robust Pre-LLM controls, AI models can occasionally include data they should not. The Post-LLM layer scans every response for personal identifiers, account numbers, and other sensitive patterns and redacts them before delivery. It also logs any incident for audit purposes.
D. Human Escalation: When AI Should Step Aside
Not every AI response should be sent to the user. The Post-LLM layer assesses the signals like how well the response is grounded in source data, whether it is consistent with known information, and whether it shows signs of uncertainty (e.g., “might,” “could,” “typically”).
| Confidence Level | What Happens |
|---|---|
|
High Confidence Well-sourced, consistent (Determinstic match) |
Delivered to the user automatically without intervention. |
|
Medium Confidence Some uncertainty detected (Low RAG score) |
Delivered with a disclaimer and logged for expert review. |
|
Low Confidence Weak grounding or contradictions (Potential hallucination) |
Escalated to human review and the user is notified of the delay. |
What Enterprises Actually Get Out of This
Most AI conversations focus on capability (i.e. what the model can do). The LLM Sandwich shifts the focus to something enterprises care about more: what the system can be trusted to do, reliably, at scale.
Here's what that looks like in practice.
- Cost comes down significantly. When simple queries are routed away from the AI entirely, and complex ones are matched to the right model tier, enterprises typically see AI compute costs drop by 60–80%.
- Hallucinations stop reaching users. The Post-LLM layer fact-checks every response against your source documents before anything goes out. Wrong answers get caught in the system itself before going any further.
- Compliance becomes systematic. Required disclosures, risk warnings or regulatory language are enforced programmatically on every response. Not because the AI remembered to include them. Because the framework ensures they're there.
- Your data stays where it should. Access controls sit in the Pre-LLM layer, outside the AI's reach. Sensitive data is never passed to the model in the first place. What the AI can't see, it can't leak. These controls also follow an organisation’s hierarchy. A junior employee, a manager, and an admin don’t see the same data and the AI respects those boundaries.
- You get an audit trail. Every query, every routing decision, every compliance check is logged. In regulated industries, this isn't a nice-to-have. It's the difference between a defensible AI deployment and a liability.
- You're not locked to any one model. The architecture is model-agnostic. Swap the LLM in the middle as better options emerge without rebuilding your governance infrastructure. Your business rules stay intact regardless of what's powering the reasoning.
- It scales without losing control. May it be a hundred users or a hundred thousand, the same rules apply to every single query. No inconsistency. No edge cases slipping through because volume went up.
The LLM Sandwich doesn't make AI more powerful. It makes it safe enough to actually use across your whole business.
From AI Pilot to Production: How to Get There
Most organisations don’t get to production-grade AI in one step. They build toward it in phases.
- It starts with routing: identifying what doesn’t need AI at all.
- Then comes context retrieval: ensuring the model works with the right data.
- Followed by access controls: defining what the AI is allowed to see.
- And finally, validation and governance: making sure what it produces is accurate, compliant, and safe to use.
That’s essentially the LLM Sandwich (the structure) we’ve covered above in the blog. It gives enterprise AI its guiding logic on how the AI model should be wrapped (so it behaves according to your business nuances).
Gyde takes that logic and turns it into execution.
To actually get this running, organisations need to figure out a lot of moving parts like what models to use, which tools to pick, how to set up data pipelines, and where these systems fit into existing workflows.
Gyde partners with your organization and helps you in your AI transformation journey. Their approach combines people, platform, and tools to take this from concept to production—delivering working AI systems in under four weeks.
See how.
How Gyde Builds Trustworthy Enterprise AI Systems?
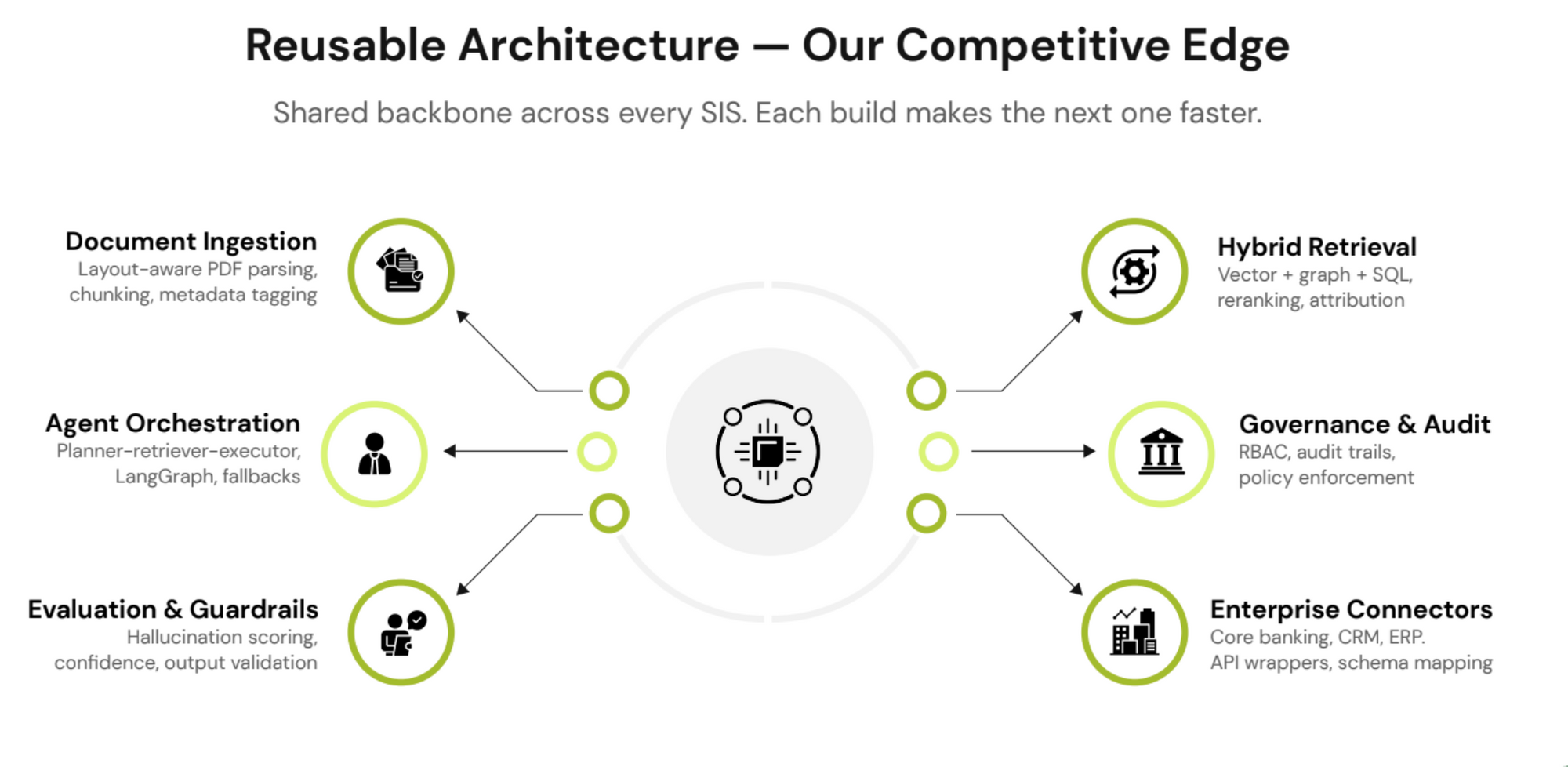
Gyde builds Specific Intelligence Systems (SIS) which are AI systems designed for a high-impact and narrow business use case, embedded directly into your workflows.
The LLM Sandwich is one part of that system. It helps structure the model. But what makes Gyde different is the full execution layer around it (the workflow, the controls, the integrations, and the delivery).
To see what this looks like in practice, take the example of the customer support AI assistant, a SIS built by Gyde. It sits inside the product as an icon and it doesn’t try to answer everything.
It focuses on one job: helping users resolve queries using past tickets, knowledge bases, and workflows already in place.
- When a user asks a question, the system first pulls the right context from past tickets and documentation. The AI generates a response based on that.
- Before the answer is shown, controls step in, ensuring the response is grounded, compliant, and appropriate for the user.
- If the issue is not fully resolved, the system doesn’t stop at an answer. Through integrations, it raises a ticket in the Help Desk System automatically, with the full conversation context already attached.
- For more complex cases, the system can launch a guided walkthrough directly on top of the application, leading the user step by step.
This way, AI handles the reasoning. The layers around it control what it accesses and when to escalate. The user just gets an answer that guides them in the flow of work and helps in decision-making. Win-win for enteprise leaders.
Behind this system is Gyde’s fundamental delivery unit — AI POD. Each pod is a 5-person team with the skills to deliver end-to-end intelligent systems. They work closely with your team to design, build, and deploy these specific intelligence systems within your environment.
This approach avoids a common enterprise AI trap: building broad systems that look impressive in demos but fail under real-world complexity.
Instead, each system is focused, structured and embedded. And once one workflow is operationalised:
- the architecture becomes reusable
- the delivery framework becomes repeatable
- the governance model stays consistent
Each new system becomes faster to deploy and easier to scale.
Bottom line: Gyde isn't just generic AI or one-size-fits-all platform—it’s an AI system built for your specific workflows, designed to work in real workflows from day one.

FAQs
How does pre-LLM routing reduce AI costs?
- Pre-LLM routing reduces AI costs as it is only used when it’s actually needed.
- A large share of queries in enterprise systems are predictable—FAQs, status checks, simple lookups. These can be handled using rules, templates, or direct database queries without involving an LLM at all.
- The pre-LLM layer identifies these cases and routes them away from the AI. Only queries that require reasoning or natural language generation are sent to the model.
- At scale, this makes a big difference. If even 30–50% of queries are handled without the LLM, you significantly cut down on compute usage.
What is the difference between RAG and an LLM?
- An LLM (Large Language Model) generates responses based on patterns it learned during training. It doesn’t have access to your company’s latest data, internal documents, or real-time updates.
- RAG (Retrieval-Augmented Generation) solves that. Instead of relying only on what the model already knows, RAG first retrieves relevant information from your knowledge base and feeds it into the prompt. The LLM then generates a response grounded in that specific, up-to-date context.
- LLM alone → answers based on general training data
- RAG → answers based on your actual, current business data
3. How is the LLM Sandwich different from just adding a chatbot to our existing systems?
A chatbot is a single-layer interface. It takes a question and returns an answer. The LLM Sandwich is a three-layer system where the AI is only one component. The pre-processing layer controls what the AI sees, and the post-processing layer controls what users receive.
A chatbot has no mechanism to enforce access controls, catch compliance gaps, or prevent hallucinations from reaching the end user. The Sandwich does all three systematically.
4. We already use RAG. Does that mean we already have part of the LLM Sandwich in place?
RAG covers one function within the Pre-LLM layer that is the context retrieval. But the full Pre-LLM layer also includes query routing, access control, input validation, and model selection. And RAG alone does nothing on the output side.
Without Post-LLM processing, a response grounded in the right documents can still contain a compliance gap, expose sensitive data, or go out without required disclosures. RAG is a component of the Sandwich, not a replacement for it.
5. How long does it take to implement an LLM Sandwich for an enterprise use case?
It depends on the complexity of the data environment and the number of systems being integrated, but the build typically follows a phased approach. Routing logic and basic context retrieval can be stood up relatively quickly.
Access controls, compliance enforcement layers, and full audit infrastructure take longer, particularly in regulated industries where validation requirements are more involved. Most organisations don't build the full stack in one go; they layer in capabilities as the system earns operational trust.