
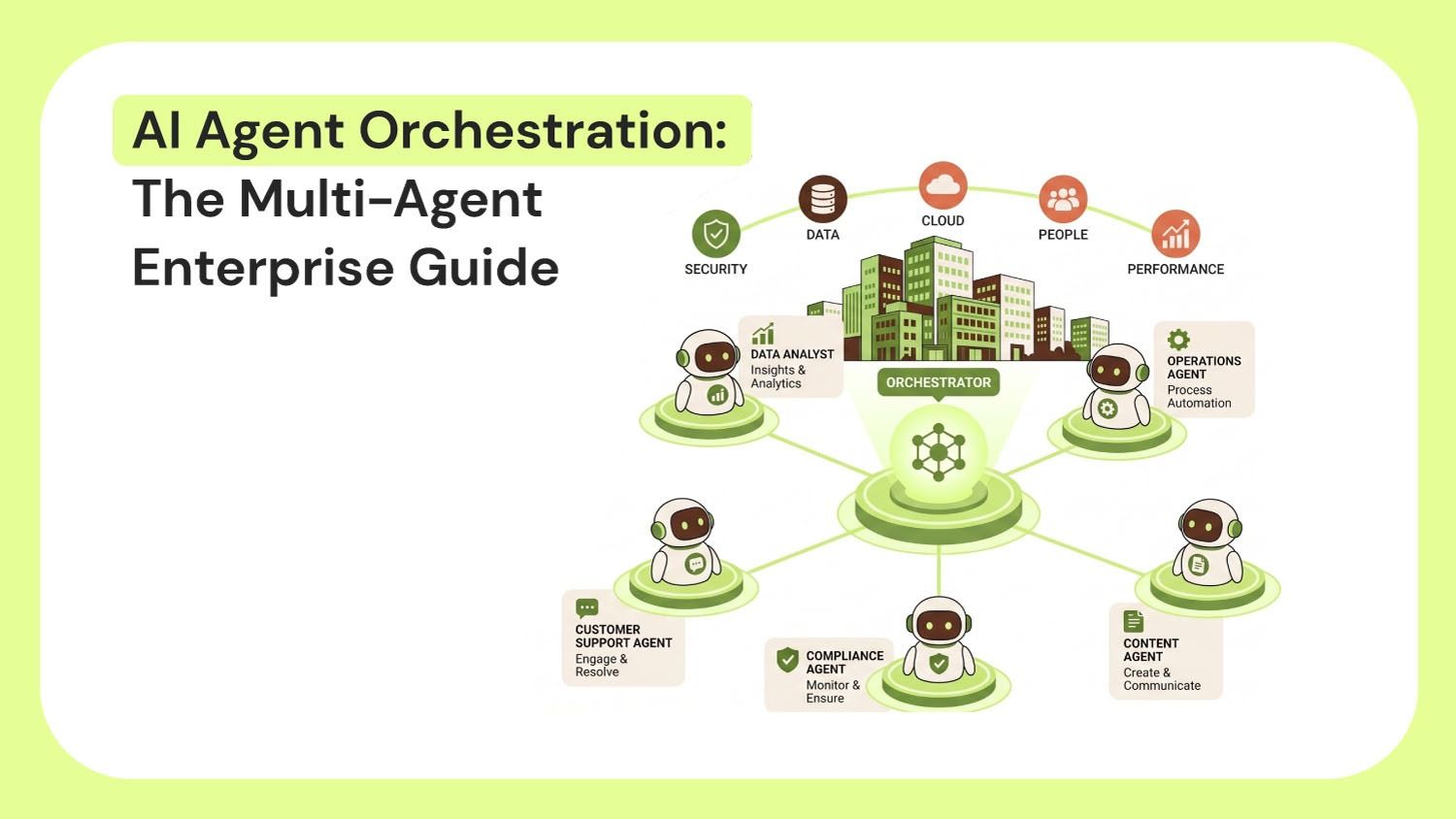
Most enterprise teams have figured out how to build an AI agent. Very few have figured out how to make several of them work together.
Orchestrating AI agents, at scale, in production, inside regulated workflows is an entirely different challenge. Because, across engineering, product, and leadership, "AI agent" rarely means the same thing twice.
For one team, it can mean an LLM with tool access. For another, it can mean a fully autonomous reasoning loop. And for some other team, it can mean a scripted workflow with a model in the middle.
Before organizations can agree on how to coordinate agents, they need to agree on what they are coordinating. Until that clarity exists, the result is going to be outputs from one system getting manually passed to the next.
Work that should flow automatically requires a human in the middle. The bottleneck moves, but it does not disappear.
This blog covers what it takes to design, govern, and run a multi-agent system that functions reliably in a real enterprise environment.
TABLE OF CONTENTS
- What AI Agent Orchestration Means
- Compounding Risk of Probabilistic Outputs in Multi-Agent Systems
- When Multi-Agent Orchestration Is the Right Choice
- Core Challenges of Multi-Agent Orchestration
- AI Agent Orchestration Frameworks: What They Solve (and Where They Fail)
- Where Multi-Agent Orchestration Is Being Applied in Enterprise
- What Production-Ready Agent Orchestration Requires
- What to Evaluate Before Choosing an Orchestration Approach
- How Gyde Orchestrates Enterprise AI Systems
- Frequently Asked Questions
What AI Agent Orchestration Means
To understand agent orchestration, you can draw parallel to a movie set.
Instead of forcing one person to write, direct, act, and edit (which guarantees a chaotic, low-quality mess), you need a specialized crew of writers, editors, and directors.
Agent Orchestration is just like the framework that manages the pipeline, routing the script to the director, looping feedback, and ensuring the final product comes together seamlessly in time (like a producer of movie would)!
New to Agentic Workflows?
Checkout this blog to understand what AI agents are, how they work, how they help inside enterprise workflows, and what it takes to deploy them in a way that earns trust and long-term value.
Read: AI Agents in Enterprise→What is AI Agent Orchestration?
AI agent orchestration is the process of coordinating multiple AI agents to accomplish a goal that no single agent could reliably complete alone. Each agent has a defined role. Each produces a specific output. And something manages how those agents work together.
That "something" is the coordinator. And understanding how it works is where most discussions about orchestration fall short.
And this is where orchestration becomes fundamentally different from automation.
Agent orchestration appears under many names across research and industry. Hover over any term below to see its definition.
Compounding Risk of Probabilistic Outputs in Multi-Agent Systems
At its core, every AI agent built on an LLM is "a probabilistic system". Meaning, it doesn't give a definitive answer. It gives a statistically likely answer for the input it received. It has no awareness of when it is uncertain.
In a single-agent system, that is manageable. Wrap guardrails around the agent. Check its output before it reaches a user or a downstream system. The risk can be contained.
In a multi-agent system, each agent's output becomes the next agent's input. Probabilistic outputs stack on top of each other across every step in the chain.
Consider a loan underwriting workflow with four sub-agents and ...
...click through each agent step to see how probabilistic outputs stack.
This is the core risk of stacked probabilistic outputs. Each agent performs within its own expected range. The system as a whole produces an outcome no individual agent would be blamed for and no one catches unless the architecture was designed to catch it.
This is also why orchestration requires more than connecting agents together. It requires designing for the places where confident-sounding outputs can still be wrong.
Which raises the next question: when is this complexity really worth introducing?
When Multi-Agent Orchestration Is the Right Choice
Multi-agent orchestration is an architecture decision.
If a single LLM (given the right context and tooling) can handle all the reasoning a workflow requires, that is the simpler and better choice. Adding agents adds coordination overhead, latency, cost, and failure surface area. None of those trade-offs are worth taking on unless the task genuinely demands it.
Multi-agent becomes the right architecture when:
Strategic Specialization Beats Generalist Fatigue
Different sub-tasks require different models with different capabilities or cost profiles. For example, a smaller model for data extraction and a larger one for narrative synthesis.
Scaling Beyond the Constraints of One Window
The workflow requires parallel reasoning across domains that cannot be held in a single context window
The Power of Parallel Autonomy
Sub-tasks are genuinely independent and can run simultaneously without creating coherence problems
Ensuring Reliability in a Multi-Format World
The output types across steps are different enough that no single agent can produce them all reliably.
In the loan underwriting example, the case for multi-agent is straightforward:
- Document parsing requires a model optimized for structured extraction.
- Risk scoring involves applying defined credit rules against retrieved data.
- Memo creation requires narrative generation.
These are genuinely different reasoning tasks, and routing them through a single agent produces a system that is mediocre at all three.
Now you must be wondering what does this look like in a real enterprise system?
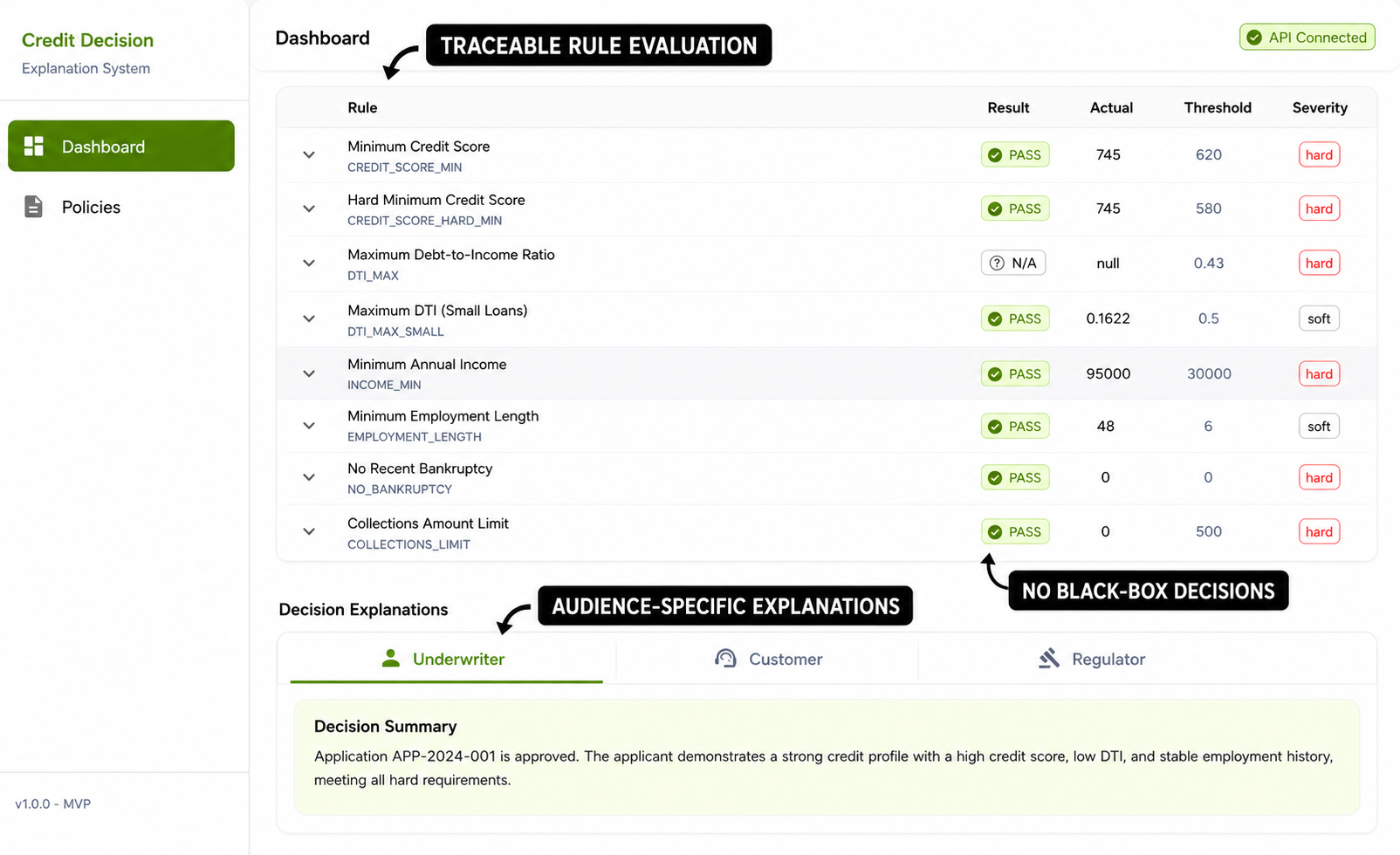
For that, take a look at Gyde’s CRE underwriting SIS (AI system). It coordinates specialized agents across policy interpretation, rule evaluation, exception handling, and decision structuring. This creates explainable underwriting workflows instead of opaque AI predictions.
Every underwriting rule is evaluated independently with traceable logic, threshold comparisons, severity classification, and audience-specific explanations for underwriters, customers, and regulators.
Core Challenges of Multi-Agent Orchestration
Before committing to this architecture, enterprise leaders should understand where the real difficulty lives.
1. Context Continuity
When the coordinator passes a task to a sub-agent, how much context does that agent receive?
In the loan underwriting example, if the document parsing agent does not know that the application fetch agent returned a file flagged as potentially incomplete, it will process the document as if it were routine.
Without proper context sharing, agents operate in isolation. This then leads to flawed downstream decisions. In multi-agent systems, context management is foundational.
2. Task Decomposition
The coordinator’s ability to break the overall goal into well-scoped sub-tasks determines the quality of the entire system.
For example, assigning “evaluate creditworthiness” as a single task may seem reasonable. But in reality, it should likely be split into data validation and risk scoring.
If one agent handles both, it ends up performing multiple probabilistic tasks instead of one focused responsibility. The result is increased ambiguity, lower reliability, and compounded downstream errors.
The decomposition problem ultimately becomes a system reliability problem.
3. Error Propagation
This is where the probabilistic nature of AI systems becomes operationally significant.
In sequential workflows, one agent’s output becomes another agent’s input. A confident but incorrect output does not stop the system. Instead, it moves forward.
The memo creation agent cannot produce a reliable underwriting summary if the risk-scoring agent worked from incomplete data. The system will not necessarily surface an obvious error.
More often, it produces a plausible-looking wrong answer. This is why orchestration systems need fail-safes at every handoff, not just at the outer boundary of the system.
4. Compliance and Auditing
In regulated environments, auditability is non-negotiable.
Organizations need visibility into questions such as:
- Which agent retrieved the data?
- What did the coordinator pass downstream?
- What triggered the final risk score?
In a single-agent system, the audit trail is relatively centralized. In a multi-agent system, it must be reconstructed across multiple agents and decision layers.
Every handoff, dependency, and reasoning path needs to remain traceable and explainable.
5. Latency and Cost
More agents mean more model calls. More model calls mean higher latency and operational cost.
A system may work technically but still fail operationally if it slows down high-volume workflows. For instance, adding 40 seconds to a process handling 500 loan applications a day can make the system impractical in production.
Latency and cost should not be treated as post-deployment optimization and scale problems. They need to be designed upfront.
AI Agent Orchestration Frameworks: What They Solve (and Where They Fail)
Frameworks like LangChain, LangGraph, CrewAI, and AutoGen give teams a set of tested structural patterns for arranging agents and controlling how work flows between them. That is genuinely useful.
The problem is that most teams select a pattern based on how it looks in documentation, not how it behaves under the conditions enterprise workflows produce: incomplete data, variable input quality, and the need to explain every decision after the fact.
That's why agent orchestration pattern/framework selection in enterprise orchestration becomes a vital decision.
Five Frameworks
Sequential Pipeline
Agents run in fixed order. Each output becomes the next agent's input.
Parallel Execution
Independent agents run simultaneously. A synthesis agent combines results.
Supervisor–Worker
A coordinator decomposes the task, dispatches to specialist agents, synthesizes their outputs.
(incomplete)
Generate–Critique–Resolve
One agent drafts, a second critiques, a third resolves.
Graph-Based Orchestration
Agents connected in a directed graph structure with conditional routing, cycles, and dynamic paths based on state.
What frameworks do not provide
Every pattern above can be implemented using open-source frameworks. What they do not provide is what makes the flow trustworthy in production like:
- output validation at each handoff,
- coordinator logic that catches incomplete outputs before they cascade,
- audit trails in a format a compliance team can use,
- and operational accountability after deployment.
The pattern handles the flow. The pattern alone does not handle the trust.
With an AI transformation partner like Gyde, trust is woven into the AI system from day one. They select patterns based on use case risk profile:
- supervisor–worker with sequential sub-pipelines for most BFSI and healthcare workflows,
- parallel execution where latency justifies the overhead,
- generate–critique–resolve where the cost of a wrong answer is highest.
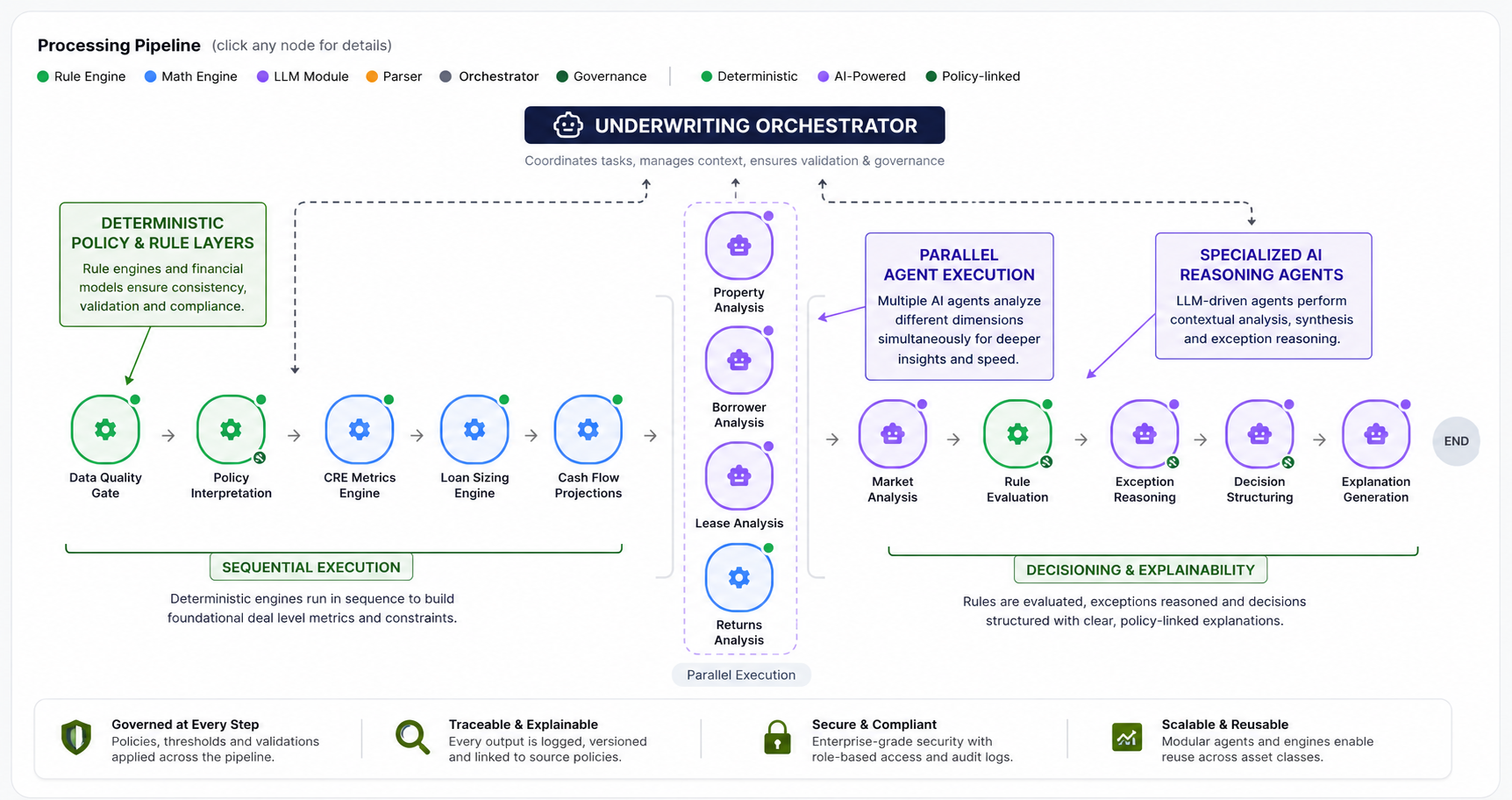
At every layer, the LLM Sandwich applies: pre-LLM rules validating inputs before each agent processes them, post-LLM rules checking outputs before they pass downstream. The pattern determines the flow. The sandwich determines whether that flow can be trusted.
Where Multi-Agent Orchestration Is Being Applied in Enterprise
Financial services
- In loan underwriting, orchestrated agents handle document retrieval, regulatory checks, and risk scoring in parallel — reducing processing time for high-volume decisions while preserving human sign-off at consequential steps.
- In KYC and AML compliance, separate agents retrieve identity documents, cross-reference sanctions lists, and flag transaction pattern anomalies simultaneously. The coordinator assembles a single compliance summary rather than routing an analyst through three separate systems.
- In trade settlement, agents validate counterparty data, check position limits, and confirm regulatory reporting requirements in parallel. Errors caught at the coordinator level before settlement instructions are issued cost significantly less than errors caught after.
- In insurance claims processing, agents extract policy details, assess damage documentation, and apply coverage rules independently. The coordinator routes edge cases (where coverage application is ambiguous) to a human adjuster before a decision is logged.
Healthcare
- Pre-authorization workflows involve agents coordinating across clinical systems, insurance APIs, and scheduling tools. Each pulls structured data from a different source. The coordinator synthesizes those outputs into a complete pre-authorization request and flags missing documentation before a clinician reviews the case.
- In clinical documentation, agents retrieve patient history, extract structured fields from unstructured consultation notes, and cross-reference medication databases for contraindications. The coordinator produces a draft summary the clinician edits rather than writes from scratch.
- In discharge planning, agents check bed availability, flag pending lab results, and verify insurance authorization for post-discharge care simultaneously. The coordinator surfaces gaps (a missing authorization, an outstanding result) before the discharge order is signed.
- In revenue cycle management, agents match procedure codes against payer rules, identify missing documentation that would trigger a denial, and draft appeal letters for flagged claims. The coordinator catches mismatches between what was billed and what the payer's rules will accept before the claim is submitted.
Retail and supply chain
- In procurement, parallel sub-agents handle vendor compliance checks, budget validation, and contract clause extraction simultaneously. The coordinator assembles their outputs into a single approval summary, reducing the manual handoffs that slow procurement cycles across geographies.
- In demand-driven replenishment, agents analyze sell-through data by SKU, check supplier lead times, and validate warehouse capacity in parallel. The coordinator generates a purchase recommendation the category manager approves.
- In supplier onboarding, agents retrieve and verify business registration documents, assess financial health indicators, and check against restricted party lists. The coordinator flags incomplete submissions and routes them back to the supplier before the onboarding team is involved.
- In returns processing, agents classify the reason for return, check warranty terms, assess resale or refurbishment eligibility, and initiate the appropriate credit workflow. The coordinator handles the routing logic (refund, replacement, or escalation) based on what each sub-agent returns.
In each scenario, the coordinator's job is to manage the probabilistic outputs of each sub-agent into a coherent, auditable result and to catch the places where those outputs, individually plausible, produce a collectively unreliable answer.
What Production-Ready Agent Orchestration Requires
The probabilistic nature of each sub-agent means production readiness in a multi-agent system requires a different standard than in a single-agent deployment.
The risk is not just that one agent fails. It is that the system produces a confident, coherent, wrong output and no one catches it until it has already influenced a decision.
Production readiness requires:
Output validation at every handoff.
The coordinator checks each sub-agent's output against expected parameters before passing it downstream. A plausible-looking output that is outside defined range should stop the chain, not continue it.
Completeness checks before sequential steps.
If an upstream agent returns partial data, the coordinator should flag it before the next agent runs — not after the final output has already been assembled from incomplete inputs.
Role-scoped access controls per sub-agent.
Each agent should access only what its specific task requires. Least privilege at the agent level reduces the surface area where a probabilistic error can reach data it should not.
Explainability at the coordinator level.
The system must be able to account for why the coordinator routed a specific task, what each sub-agent received, and what triggered the final output. In regulated environments, this is not optional.
Predefined human escalation paths.
When a sub-agent's output falls outside expected parameters, the escalation route should already exist. Escalation logic that is improvised when something goes wrong is not a safety mechanism.
Adversarial testing before go-live.
Specifically, testing for the compounding failure case where each individual sub-agent returns a plausible but incorrect output, and the system produces a wrong final result without surfacing an error.
Rollback capability.
If a problem is detected mid-workflow, the system needs to stop further processing and alert the right people. A system that detects an anomaly and continues anyway is not production-ready.
What to Evaluate Before Choosing an Orchestration Approach
For enterprise teams reviewing multi-agent orchestration approaches, a few questions separate mature implementations from promising pilots:
- Is multi-agent actually necessary here? Does the use case require multiple LLMs, or can a single well-structured agent handle the full workflow?
- How does the coordinator handle a sub-agent that returns a plausible but incomplete output — not an error, but a confident answer built on partial data?
- What does the audit trail look like at the sub-agent level? Can it trace which agent retrieved what data and what the coordinator decided to pass downstream?
- Where are the human checkpoints, and are they predefined or improvised when something goes wrong?
- How is each sub-agent tested for the compounding failure case — where individual outputs are within range but the combined output is wrong?
- Who owns the system's performance in production and is that accountability clearly assigned?
- When the underlying model for a sub-agent is updated, does the coordinator logic need to be rebuilt?
These are architecture and vendor evaluation questions. The earlier they get asked, the fewer surprises appear at deployment.
How Gyde Build & Orchestrates Enterprise AI Systems
Agent orchestration is just one part of what Gyde builds.
Gyde builds Specific Intelligence Systems (SIS) — production-grade AI systems that combine enterprise data retrieval, orchestration, governance, deployment infrastructure, and AI agents around a single business bottleneck.
When a use case requires multiple agents, Gyde adds a coordinator layer that manages task routing, context transfer, validation, and escalation across the system.
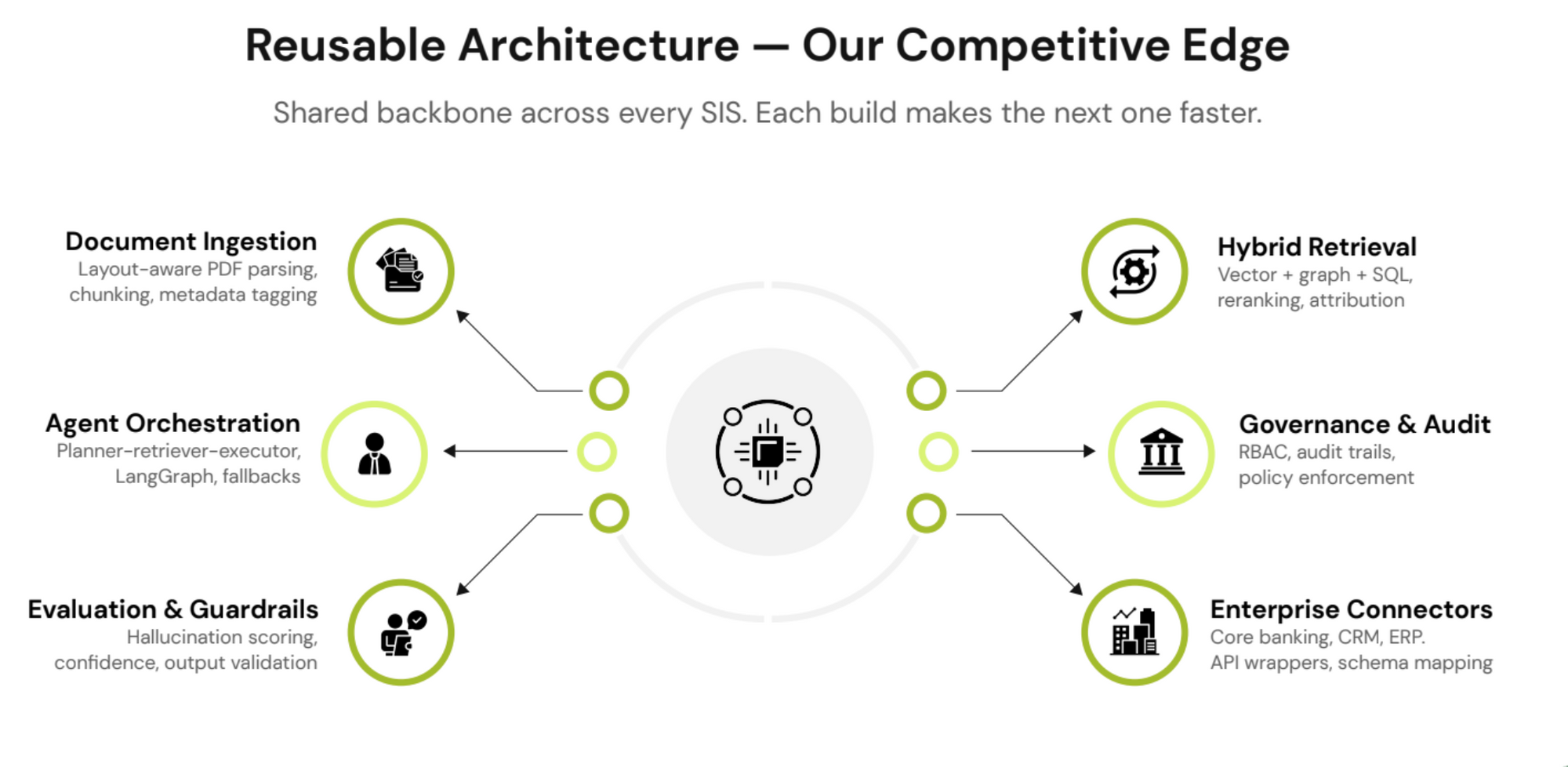
The orchestration layer connects enterprise systems, retrieval pipelines, middleware, governance controls, deployment infrastructure, and specialized agents into a single operational system.
The goal is reliable enterprise-graded AI execution.
In multi-agent systems, failures usually happen during handoffs between agents when incomplete context or unchecked outputs move downstream. Gyde validates every handoff before execution continues.
To deliver these systems, Gyde deploys a dedicated AI PODs that build, operate, monitor, and continuously improve orchestration performance in production.
Solving one departmental bottleneck establishes a reusable architecture, allowing each successive deployment to happen faster and more efficiently.

FAQs
What is the difference between a coordinator agent and a regular AI agent?
- A coordinator agent does not perform domain-specific tasks. Its job is to decompose the overall goal, assign sub-tasks to purpose-built agents, and synthesize their outputs into a coherent result.
- A regular agent executes a specific task within that structure. In a well-designed multi-agent system, the coordinator holds the full picture. Each sub-agent holds only what it needs.
When should an enterprise choose multi-agent orchestration over a single agent?
The clearest trigger is when a use case requires multiple LLMs to function correctly because different sub-tasks require different models, contexts, or reasoning approaches that a single agent cannot handle reliably.
If a single agent with well-structured tooling can handle the full workflow, that is usually the better choice. Multi-agent adds coordination complexity that is only worth the trade-off when the task genuinely demands it.
How do you maintain compliance in a multi-agent system?
Compliance controls need to be applied at every handoff, not just at the outer boundary of the system. This means pre- and post-processing rules at the sub-agent level, role-based access controls scoped to each agent's task, and audit logging that traces decisions across every step.
In regulated environments, the audit trail needs to be able to answer: which agent produced this, with what data, and why.
What happens when a sub-agent fails mid-workflow?
A production-ready orchestrated system needs a defined response to sub-agent failure. This includes retry logic, rerouting to an alternative path, and predefined escalation to a human reviewer when the failure cannot be automatically resolved.
Systems that only log errors and continue are not production-ready. Errors in one sub-agent become inputs to the next, and they compound.
Is fully autonomous agent orchestration viable in regulated industries?
Not at consequential decision points. Fully autonomous orchestration removes the human checkpoints that regulated environments require for decisions that carry financial, legal, or clinical risk.
The more productive question is where autonomy is appropriate (high-volume, low-risk sub-tasks) and where human review is required, which should be determined by the risk profile and regulatory context of each specific workflow.